 公众号
公众号Sandy Bridge特性曝光 六大亮点为整合奠基
2010-12-16 23:00:00
- +1 你赞过了
【天极网DIY硬件频道】Sandy Bridge是intel不久就会推出的新处理器代号名称,网上也有称为SNB的。按照TICK时间,Intel处理器在2009年会迈入32纳米时代,按照tock时间在2010年会推出应用32纳米技术的Sandy Bridge处理器。从2007年开始这种规律性的性能提升已经让大家过足了性能提升瘾,那么即将发布的Sandy Bridge处理器又将带来什么样的惊喜呢?依据笔者从各种途径得来的消息,总体上新的处理器具备以下六大亮点:
一、新一代Turbo Boost
Lynnfield Core i7/i5首次引入了智能动态加速技术“Turbo Boost”(睿频),能够根据工作负载,自动以适当速度开启全部核心,或者关闭部分限制核心、提高剩余核心的速度,比如一颗热设计功耗(TDP)为 95W的四核心处理器,可能会三个核心完全关闭,最后一个大幅提速,一直达到95W TDP的限制。

Sandy Bridge新一代Turbo Boost
现有处理器都是假设一旦开启动态加速,就会达到TDP限制,但事实上并非如此,处理器不会立即变得很热,而是有一段时间发热量距离TDP还差很多。
Sandy Bridge利用这一点特性,允许单元控制单元(PCU)在短时间内将活跃核心加速到TDP以上,然后慢慢降下来。PCU会在空闲时跟踪散热剩余空间,在系统负载加大时予以利用。处理器空闲的时间越长,能够超越TDP的时间就越长,但最长不超过25秒钟。
不过Sandy Bridge在稳定性方面,PCU不会允许超过任何限制。之前我们也已经说过了,Sandy Bridge GPU图形核心也可以独立动态加速,最高可达惊人的1.35GHz。如果软件需要更多CPU资源,那么CPU就会加速、GPU同时减速,反之亦然。
二、AVX指令集
在Sandy Bridge中最重要的应用恐怕就是AVX(高级矢量扩展)技术,这项新技术据说可以大幅度提升处理器在高密集浮点运算中的性能。intel宣称,使用AVX技术进行矩阵计算的时候将比SSE技术快90%。

Sandy Bridge加入了全新的AVX高级矢量指令集
三、整合高性能GPU
在之前的intel架构中也有整合图形核心存在,比如现在的酷睿i3以及奔腾E6500等。它们虽然也自带了图形核心,但与CPU是双内核封装,只是通过45nm工艺、更多着色硬件、更高频率提升了性能。Sandy Bridge则不然,CPU、GPU封装在同一内核中,全部采用32nm工艺,特别是显著提高了IPC(指令/时钟)。
Sandy Bridge GPU有自己的电源岛和时钟域,也支持Turbo Boost技术,可以独立加速或降频,并共享三级缓存。显卡驱动会控制访问三级缓存的权限,甚至可以限制GPU使用多少缓存。将图形数据放在缓存里就不用绕道去遥远而“缓慢”的内存了。这样不仅功耗得到了有效的控制,而且性能也得到了显著的提升。

Sandy Bridge结构里会整合高性能GPU
之前的intel图形核心GPU的寄存器是临时分配,一个线程被占用较少的时候其它线程会分配剩余的寄存器。这样有的时候会出现线程无寄存器可用的局面,虽然核心面积得到有效控制和利用,但是性能反而会降低不少。而在Sandy Bridge中每个线程均会固定分配120个寄存器,较之以前提升了近两倍,比Westmere HD Graphics的80个还多一半。
综合之前的多种技术,现在的Sandy Bridge中的GPU每个EU的指令吞吐量都比现在的HD Graphics增加了一倍。
四、媒体引擎
除了GPU图形核心,Sandy Bridge中还有一个媒体处理器,专门负责视频解码、编码。新的硬件加速解码引擎中,整个视频管线都通过固定功能单元进行解码,和现在正好相反。Intel据此宣称,Sandy Bridge在播放视频的时候功耗可降低一半。
Sandy Bridge中将单独设立编码解码的媒体引擎
Sandy Bridge视频编码引擎则是全新的。具体细节没有公布,但是在Intel曾经的IDF大会现场中拿出了一段3分钟长的1080p 30Mbps高清视频,将其转换成640×360 iPhone格式,结果整个过程耗时非常短仅用时14秒(intel IDF大会演示),而这只花费了大约3平方毫米的核心面积。Intel与软件产业合作密切,相信这种视频转码技术会很快得到广泛支持。
五、环形总线
在Sandy Bridge中我们将会看到一个和以往不大一样的总线架构,在新处理器中会出现一个和服务器版的Nehalem-EX、Westmere-EX类似的架构,每个核心、每一块三级缓存(LLC)、集成图形核心、媒体引擎、系统助手(System Agent)都在这条线上拥有自己的接入点,就如同一个公用的平台一样。这条环形总线由四条独立的环组成,分别是数据环(DT)、请求环(QT)、响应环(RSP)、侦听环(SNP)。每条环的每个站台在每个时钟周期内都能接受32字节数据,而且环的访问总会自动选择最短的路径,以缩短延迟。随着核心数量、缓存容量的增多,缓存带宽也随时同步增加,因而能够很好地扩展到更多核心、更大服务器集群。

Sandy Bridge全新的环形架构
这样,Sandy Bridge每个核心的三级缓存带宽都是96GB/s,堪比高端Westmere,而四核心系统更是能达到384GB/s,因为每个核心都在环上有一个接入点。三级缓存的延迟也从大约36个周期减少到26-31个周期。此前预览的时候我们就已经感觉到了这一点,现在终于有了确切的数字。三级缓存现在被划分成多个区块,分别对应一个CPU核心,都在环形总线上有自己的接入点和完整缓存管线。每个核心都可以访问全部三级缓存,只是延迟不同。此前三级缓存只有一条缓存管线,所有核心的请求都必须通过它,现在很大程度上分而治之了。
和以前不同的是,三级缓存的频率现在也和核心频率同步,因而速度更快,不过缺点是三级缓存也会随着核心而降频,所以如果CPU降频的时候GPU又正好需要访问三级缓存,速度就慢下来了。
六、寄存器改进
Sandy Bridge里又增加了一个微指令缓存,用于在指令解码时临时存放。在取硬件获得一个新指令的时候,首先检查它是否存在于微指令缓存中,如是前端关闭缓存为其余管线服务,结束了这个X86管线中非常复杂的过程,能够节约大量功耗。
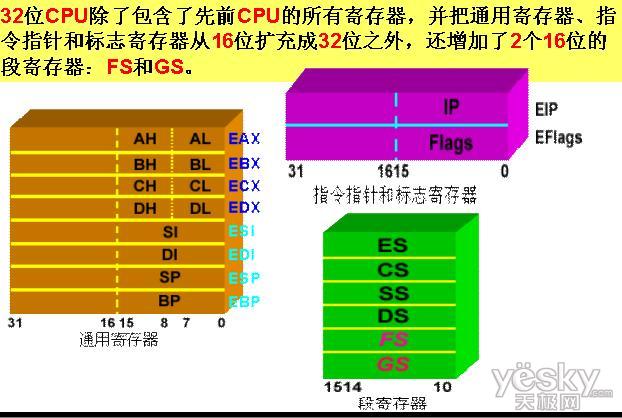
寄存器部分改进也是Sandy Bridge的一大亮点
和AMD的推土机、山猫一样intel也引入了物理寄存器。Core Duo时代是80-bit,加入SSE指令集后增至128-bit,现在又有了AVX指令集,按照趋势会翻番至256-bit。微指令缓存的彻底改变了原由的模式,微指令在乱序执行引擎中只会携带指向操作数的指针,而非数据本身。有效的减少了转移数据时数据流的吞吐量,降低了功耗减少了核心面积。这样AVX指令集才得以实现,以最小的核心面积代价,Intel将所有SIMD单元都转向了256-bit。AVX支持256-bit操作数,相当消耗晶体管与核心面积,而RPF的使用加大了乱序执行缓冲,能够很好地满足更高吞吐量的浮点引擎。
借由128bit的整数SIMD数据路径实现每周期内进行两个256-bit AVX操作,而原有128bit通道的功耗并不会因此而改变。AMD推土机架构对AVX的支持则有所不同,使用了两个128-bit SSE路径来合并成256-bit AVX操作,即使八核心(四模块)推土机的256-bit AVX吞吐量也要比四核心Sandy Bridge少一半。Sandy Bridge架构中载入和存储地址端口是对称的,都可以执行载入或者存储地址,载入带宽因此翻倍。 Sandy Bridge的整数执行也有了改进,只是比较有限。ADC指令吞吐量翻番,乘法运算可加速25%。











玉米
最新资讯
热门视频
新品评测
 X
X

 微博认证登录
微博认证登录
 QQ账号登录
QQ账号登录
 微信账号登录
微信账号登录


























